Causality in Video Diffusers is Separable from Denoising
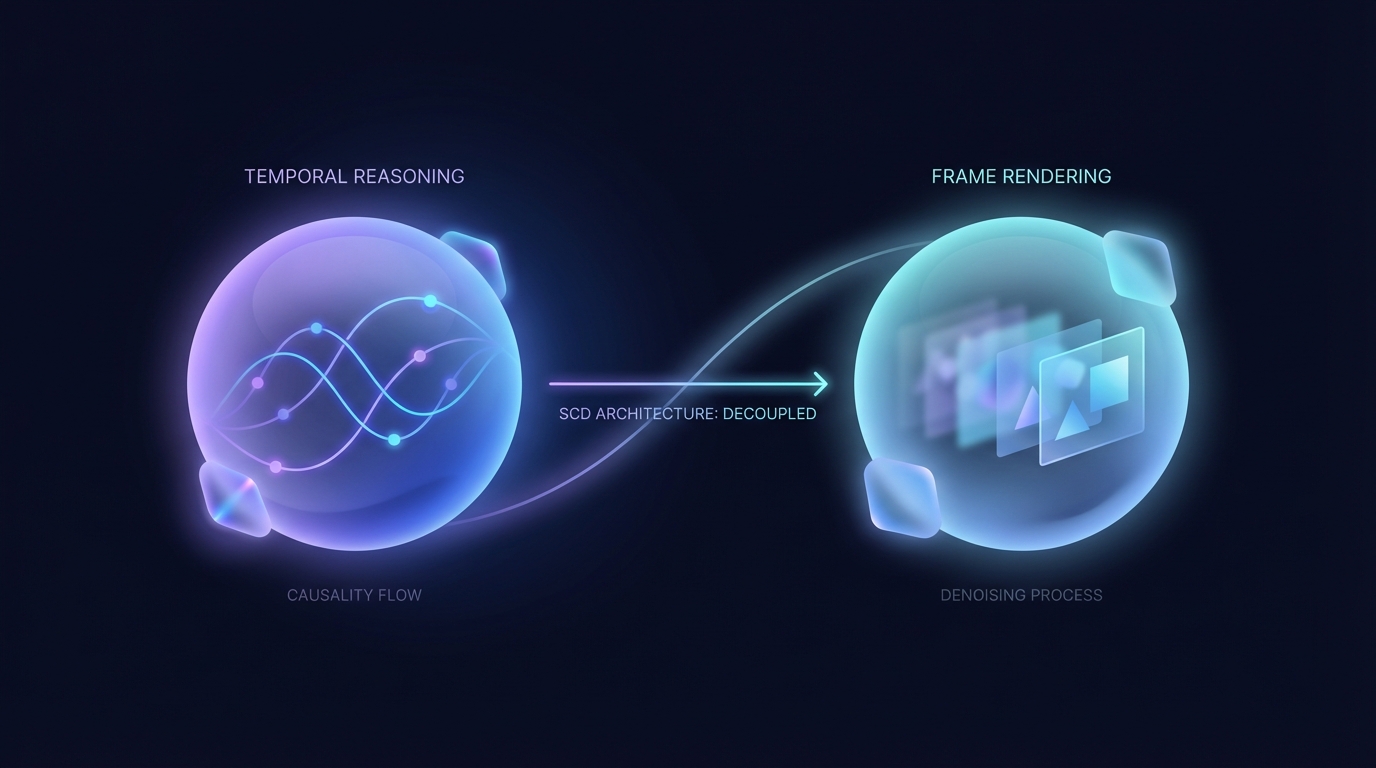
Image generated by Gemini AI
A new architecture, Separable Causal Diffusion (SCD), has been developed to enhance causal diffusion models used in video generation. By decoupling temporal reasoning from multi-step frame rendering, SCD improves efficiency, achieving higher throughput and reduced latency. Experiments show it matches or exceeds the quality of existing models, making it a promising innovation in generative processes.
Causality in Video Diffusers Separable from Denoising
A recent study reveals that causal reasoning in video diffusion models can be distinctly separated from the denoising process. Researchers demonstrated that decoupling causal attention from iterative denoising steps can improve efficiency and output quality.
The paper identifies two significant findings through the examination of autoregressive video diffusers. Early layers generate highly similar features across different denoising steps, leading to redundant computations. Deeper layers display sparse cross-frame attention, focusing more on rendering within individual frames.
In response, the researchers introduced a new architecture called Separable Causal Diffusion (SCD). This model employs a causal transformer encoder to handle temporal reasoning on a per-frame basis while utilizing a lightweight diffusion decoder for rendering. This separation enhances performance metrics.
Experiments on various benchmarks indicate that SCD not only matches but often exceeds the generation quality of existing causal diffusion models, with significant improvements in throughput and per-frame latency.
Related Topics:
📰 Original Source: https://arxiv.org/abs/2602.10095v1
All rights and credit belong to the original publisher.