Diffusion-DRF: Differentiable Reward Flow for Video Diffusion Fine-Tuning
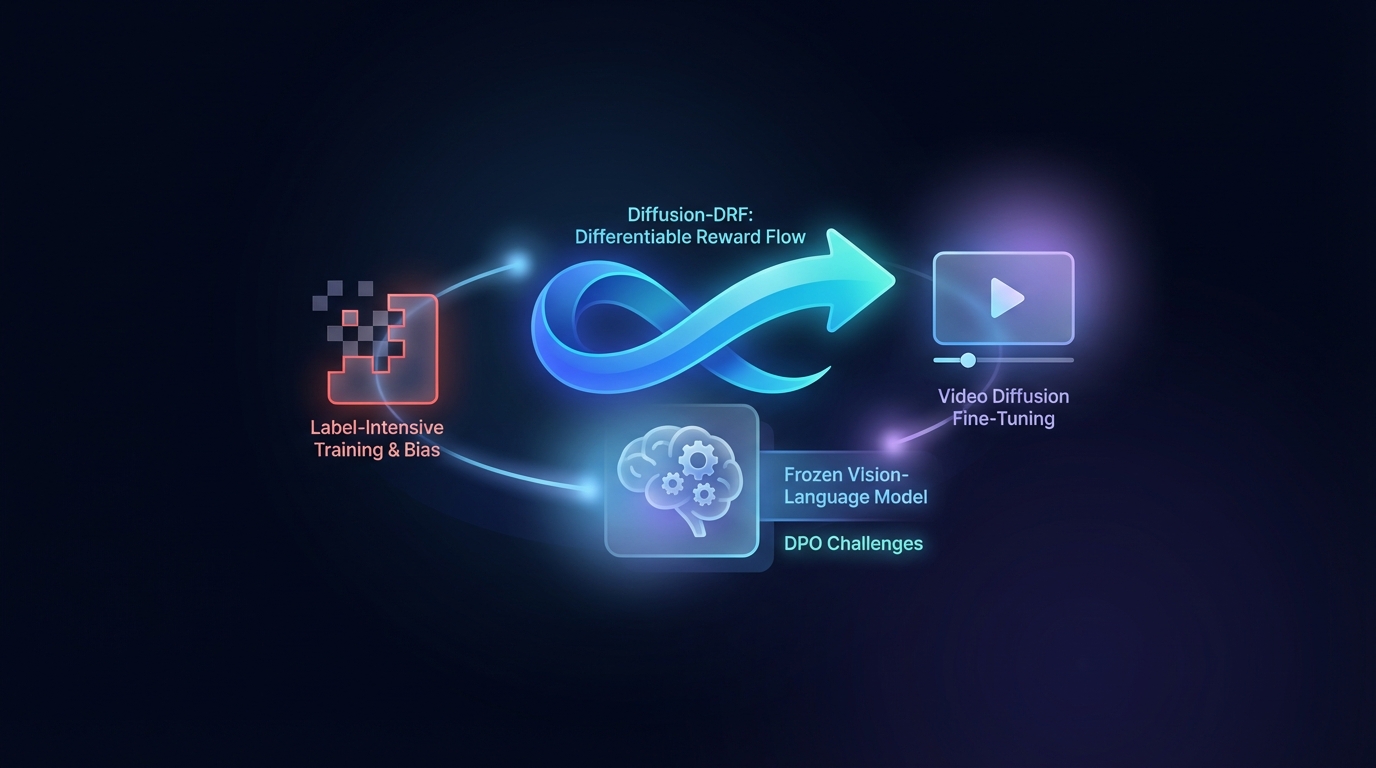
Image generated by Gemini AI
Direct Preference Optimization (DPO) enhances Text-to-Video generation but faces challenges with label-intensive training and bias. The proposed Diffusion-DRF method uses a frozen Vision-Language Model as a differentiable critic, allowing for efficient backpropagation of feedback through video diffusion models. This approach improves video quality and semantic alignment while reducing reward hacking issues, and is adaptable to other diffusion-based tasks without needing additional reward models.
Diffusion-DRF: A Breakthrough in Video Diffusion Fine-Tuning
Researchers have introduced Diffusion-DRF, a novel method for fine-tuning video diffusion models that enhances video quality and semantic alignment. This approach leverages a frozen Vision-Language Model (VLM) as a training-free critic, marking a significant advancement over existing methods.
Diffusion-DRF addresses common challenges in traditional Text-to-Video (T2V) generation by integrating feedback from the VLM directly into the diffusion denoising chain. This method allows for the backpropagation of VLM feedback, converting logit-level responses into token-aware gradients that facilitate optimization, effectively mitigating issues related to reward hacking and model collapse.
Notably, Diffusion-DRF is model-agnostic, applicable to various diffusion-based generative tasks beyond T2V generation, positioning it as a valuable tool for future advancements in video generation.
Related Topics:
📰 Original Source: https://arxiv.org/abs/2601.04153v1
All rights and credit belong to the original publisher.