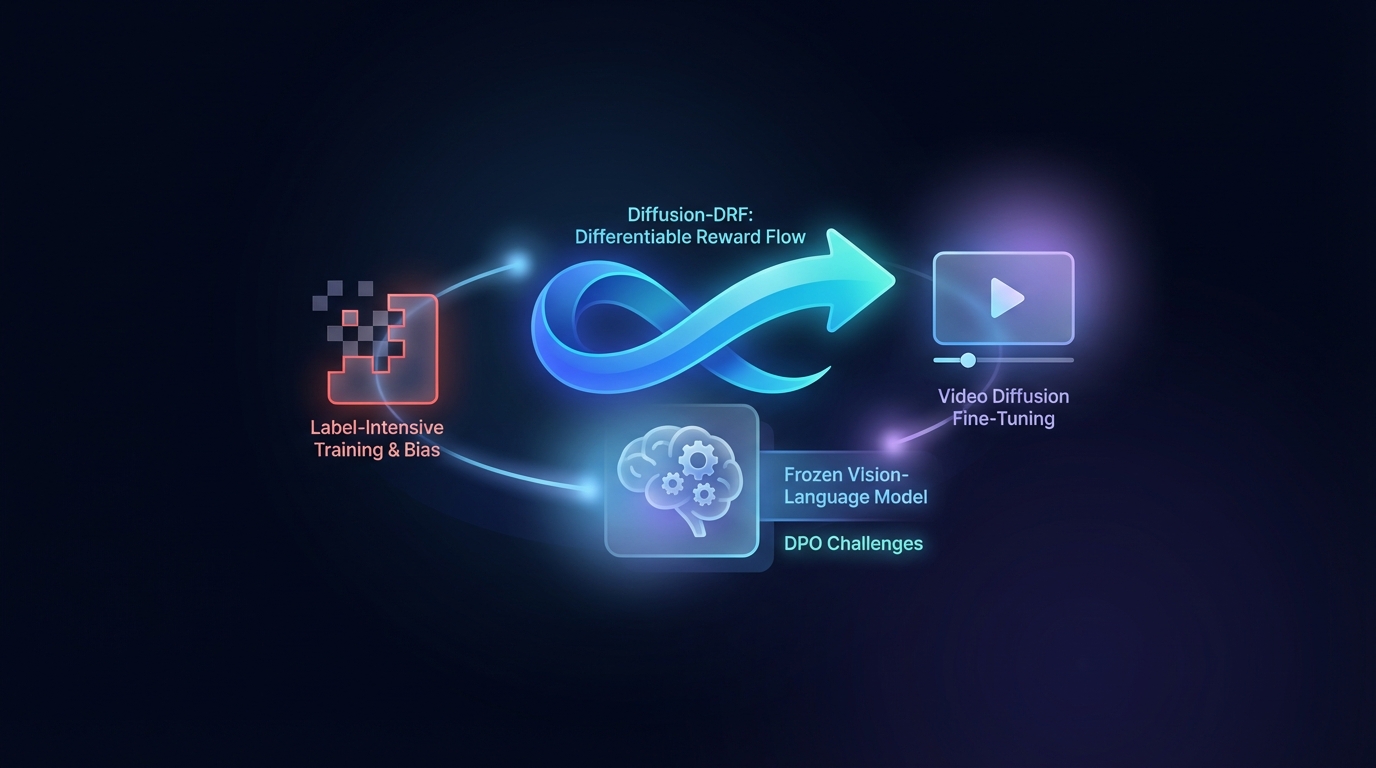
Diffusion-DRF: Differentiable Reward Flow for Video Diffusion Fine-Tuning
Direct Preference Optimization (DPO) enhances Text-to-Video generation but faces challenges with label-intensive training and bias. The proposed Diffusion-DRF method uses a frozen Vision-Language Model as a differentiable critic, allowing for efficient backpropagation of feedback through video diffusion models. This approach improves video quality and semantic alignment while reducing reward hacking issues, and is adaptable to other diffusion-based tasks without needing additional reward models.
arXiv